5차시 데이터 조작과 트랜잭션, 데이터 무결성과 제약 조건
13. UPDATE 문은 테이블에 저장된 데이터를 수정하기 위한 DML입니다. WHERE 절을 생략하면 테이블에 있는 모든 행이 수정됩니다.
UPDATE table_name
SET column_name1 = value/, column_name2 = value2, •••
WHERE conditions;
WHERE 절로 특정 로우만 수정하기
01:update dept_copy
02:set dname=‘PROGRAMMING’
03:where dno=10;
부서명이 모두 수정되었음을 확인할 수 있습니다.
DNO DNAME LOC
10 PROGRAMMING NEW YORK //특정 로우만 수정
20 RESEARCH DALLAS
30 SALES CHICAGO
40 OPERATIONS BOSTON
14. 데이터 무결성 제약 조건(Data Integrity Constraint Rule)이란 테이블에 유효하지 않은 (부적절한) 데이터가 입력되는 것을 방지하기 위해서 테이블을 생성할 때 각 칼럼에 대해 정의하는 여러 가지 규칙을 말합니다. 이러한 제약 조건은 새로운 데이터가 삽입되거나 기존 데이터가 수정, 삭제 될 때에 적용됩니다.
테이블에 부적절한 데이터가 입력되지 않고 무결한 데이터만 유지할 수 있도록 하기 위해 오라클에서 지원되는 제약 조건은 5가지입니다.
NOT NULL - 칼럼에 NULL 값을 포함하지 못하도록 지정한다.
UNIQUE - 테이블의 모든 로우에 대해서 유일한 값을 갖도록 한다.
PRIMARY KEY - 테이블의 각 행을 식별하기 위한 것으로 NULL과 중복된 값을 모두 허용하지 않는다. 즉. NOT NULL 조건과 니NIQ니E 조건을 결합한 형태이다.
FOREIGN KEY - 참조되는 테이블에 칼럼 값이 항상 존재해야 한다.
CHECK - 저장 가능한 데이터 값의 범위나 조건을 지정하여 설정한 값만을 허용한다.
제약 조건은 일반적으로 테이블이 생성될 때 생성되지만 그 후에도 ALTER TABLE로 제약 조건을 추가할 수 있으며 삭제도 가능합니다.
15. CHECK 제약 조건은 칼럼에서 허용 가능한 데이터의 범위나 조건을 정의합니다. 입력되는 값을 체크하여 설정된 값 이외의 값이 들어오면 오류 메시지와 함께 명령이 수행되지 못하게 하는 것입니다. 조건으로 데이터 값의 범위나 특정 패턴의 숫자나 문자 값을 설정할 수 있습니다. 데이터를 입력하거나 수정할 때 실수로 부정확한 값을 입력하는 것을 막을 수 있습니다. 칼럼에 정의할 수 있는 CHECK 제약 조건의 수에는 제한이 없기 때문에 하나의 칼럼에 여러 개의 CHECK 제약 조건을 정의할 수 있습니다. CURRVAL, NEXTVAL, ROWNUM과 같은 의사 칼럼이나 SYSDATE,USER와 같은 함수에는 사용 할 수 없습니다.
6차시 뷰, 시퀀스와 인덱스
16. FORCE 옵션은 기본 테이블의 존재 유무에 상관없이 뷰를 생성해야 할 경우에 사용하며 NOFORCE 옵션은 반드시 기존 테이블이 존재할 경우에만 뷰를 생성합니다. FORCE, NOFORCE 옵션 중 하나를 지정해야 하는데 특별한 설정이 없으면 NOFORCE 옵션이 지정된 것으로 간주합니다.
17. 시퀀스의 현재 값을 알아내기 위해서 CURRVAL를 사용하고,다음 값을 알아내기 위해서 는 NEXTVAL를 사용합니다. CURRVAL에 새로운 값이 할당되기 위해서는 NEXTVAL로 새로운 값을 생성해야 합니다. 즉, NEXTVAL로 새로운 값을 생성한 다음에 이 값을 CURRVAL에 대체하게 됩니다.
NEXTVAL, CURRVAL을 사용할 수 있는 경우와 사용할 수 없는 경우를 살펴봅니다.
• NEXTVAL, CURRVAL을 사용할 수 있는 경우
-서브 쿼리가 아닌 SELECT 문
-INSERT 문의 SELECT 절
-INSERT 문의 VALUE 절
-UPDATE 문의 SET 절
• NEXTVAL, CURRVAL을 사용할 수 없는 경우
-VIEW의 SELECT 절
-DISTINCT 키워드가 있는 SELECT 문
-GROUP BY, HAVING, ORDER BY 절이 있는 SELECT 문
-SELECT, DELETE, UPDATE의 서브 쿼리
-CREATE TABLE, ALTER TABLE 명령의 DEFAULT 값
18. 인덱스의 종류는 유일한 값을 갖는지 여부에 따른 고유 인덱스(Unique Index)와 비 고유 인덱스(Non Unique Index), 인덱스를 구성하는 칼럼의 개수에 따라 단일 인덱스(Single Index)와 결합 인덱스(Composite Index), 함수에 인덱스를 지정하는 함수 기반 인덱스 (Function Based Index) 등이 있습니다.
(1) 고유/비 고유 인덱스
고유 인덱스는 기본 키나 유일 키처럼 유일한 값을 갖는 칼럼에 대해서 생성하는 인덱스를 말하며 비 고유 인덱스는 중복된 데이터를 갖는 칼럼에 대해서 생성하는 인덱스를 말합니다. 인덱스를 생성하면서 UNIQUE 옵션을 추가하면 고유 인덱스가 생성되며 UNIQUE 옵션을 생략하면 비 고유 인덱스가 생성됩니다.
(2) 결합 인덱스
지금까지 생성한 인덱스들처럼 한 개의 칼럼으로 구성한 인덱스는 단일 인덱스입니다. 두 개 이상의 칼럼으로 인덱스를 구성하는 것을 ‘결합 인덱스’라고 합니다.
(3) 함수 기반 인덱스
함수 기반 인덱스는 수식이나 함수를 적용하여 만든 인덱스를 말합니다.
7차시 사용자 권한과 PL/SQL
19. 롤(role)은 여러 사용자가 다양한 권한을 효과적으로 관리할 수 있도록 관련된 권한끼리 묶어 놓은 것입니다. 사용자를 생성한 후 사용하려면 여러 개의 권한들을 부여해야 하는데 롤은 사용자가 기본적으로 가져야 할 여러 종류의 권한을 일일이 부여하는 번거로움을 덜어 줍니다. 롤은 사용자에게 보다 간편하게 권한을 부여할 수 있도록 한다는 장점이 있습니다.
롤은 크게 사전 정의된 롤과 사용자가 정의한 롤로 구분됩니다. 사전 정의된 롤은 오라클 데이터베이스를 설치하면 기본적으로 제공되는 롤이고, 사용자가 정의한 롤은 사용자가 직접 롤을 정의하여 사용하는 것을 말합니다. 사전 정의된 롤의 종류는 다음과 같습니다.
DBA 롤은 시스템 자원을 무제한적으로 시용하며 시스템 관리에 필요한 모든 권한을 부여 할 수 있는 강력한 권한을 보유한 롤입니다. 그러므로 사용자들이 소유한 데이터베이스 객체를 관리하고 사용자들을 작성,변경,제거할 수 있는 모든 권한을 갖습니다.
CONNECT 롤은 사용자가 데이터베이스에 접속 가능하도록 가장 기본적인 시스템 권한 8가지를 그룹화한 것입니다.
RESOURCE 롤은 사용자가 객체(테이블,뷰, 인덱스)를 생성할 수 있도록 하기 위해서 시스템 권한을 그룹화한 것입니다.
20. LOOP 문
여러 번 반복적으로 수행되는 문장이 있을 경우 LOOP 문을 이용합니다. LOOP 문의 종류에는 BASIC LOOP, FOR LOOP, WHILE LOOP 3가지가 있습니다. BASIC LOOP 문은 조건 없이 반복 작업을 위해 시용합니다. FOR LOOP 문은 COUNTS 기본으로 한 반복 작업을 위해 사용합니다. WHILE LOOP 문은 조건을 비교하기 위한 반복 작업에 사용합니다. 반복문을 종료하기 위해서는 EXIT 문을 사용합니다.
BASIC LOOP는 가장 간단한 구조의 루프로 LOOP와 END LOOP 사이에 반복 수행할 문장을 기술합니다.
LOOP
statenent1;
statement2;
EXIT [WHERE condition];
END LOOP
실행 상의 흐름이 END LOOP에 도달하면 그와 짝을 이루는 LOOP 문으로 제어가 돌아 갑니다. 이러한 루프를 ‘무한 루프’라 하며,루프를 벗어나려면 EXIT 문을 시용합니다. 조건에 따라 LOOP를 종료하기 위해서는 WHEN 절을 기술합니다. WHEN 절 다음에 기술 한 조건이 참이면 EXIT 문이 수행되어 더 이상 반복하지 않고 END LOOP 다음으로 제어가 옮겨져서 LOOP를 종료합니다.
8차시 프로시저와 함수와 트리거, 데이터베이스 설계
21. SELECT 문의 수행 결과가 여러 개의 로우로 구해지는 경우에 모든 로우에 대해 처리를 하려면 커서를 사용해야 합니다. 커서는 CURSOR, OPEN, FETCH, CLOSE 4단계 명령에 의해서 사용됩니다.
DECLARE
CURSOR cursor_name IS statement;
BEGIN
OPEN cursor_name;
FECTCH cur_name INTO variable_name;
CLOSE cursor_name;
END;
22. 프로시저
PL/SQL 프로그램의 종류는 Procedure, Function, Trigger로 나뉩니다. 프로시저는 일련의 작업들을 하나로 묶어서 저장해 두었다가 호출하여 이런 작업들이 실행할 수 있게 해줍니다. 프로시저는 복잡한 SQL 문을 단순화시켜 준다는 장점이 있습니다. 또한 생성한 프로시저는 여러 번 반복하고 호출하여 사용할 수 있습니다. CREATE PROCEDURE 문으로 프로시저를 생성합니다.
CREATE [OR REPLACE] PROCEDURE procedure_name
(argument1 [mode] data_taye,
argument2 [mode] data_taye ...
)
IS
local_variable declaration
BEGIN
statement1;
statements2;
END;/
23. 트리거(trigger)는 연쇄 반응 • 생리 현상 • 일련의 사건 등을 유발하는 자극과 같은 사전적인 의미를 갖습니다. 오라클에서의 트리거는 어떤 이벤트가 발생했을 때 내부적으로 실행되도록 데이터베이스에 저장된 프로시저를 말합니다.
트리거 역시 프로시저나 함수와 같이 선언부,실행부, 예외부를 갖는 PL/SQL 블록 구조를 가지고 있습니다. 함수나 프로시저는 사용자가 원할 때 EXECUTE 문으로 직접 호출하지만 트리거는 이를 호출하는 명령어가 따로 존재하지 않습니다. 트리거는 실행되어야 할 이벤트가 발생하게 되면 자동으로 실행되는 프로시저입니다. 이벤트는 DML 문인 INSERT, DELETE, UPDATE에 의해서 테이블에 어떤 변화가 발생하는 것을 말합니다.
DML 트리거의 종류는 크게 AFTER 트리 거와 BEFORE 트리거로 나뉩니다.
• AFTER 트리거
테이블에 INSERT, UPDATE, DELETE 등의 작업이 일어난 후에(After) 작동합니다. 테이블에만 작동하며 뷰에는 작동하지 않습니다.
• BEFORE 트리거
테이블이나 뷰에 이벤트가 작동하기 전에 작동합니다. 테이블뿐 아니라 뷰에도 작동이 되며, 주로 뷰가 업데이트 가능하도록 사용합니다. INSERT, UPDATE, DELETE 세 가지 이벤트로 작동합니다.
24. 관계 타입은 엔티티-관계 모텔에서 엔티티 사이의 연관성을 표현하는 개념으로 두 개의 엔티티 타입 사이의 업무적인 연관성을 논리적으로 표현한 것입니다. 이러한 관계를 정의할 때 동사구로 관계를 정의하며 엔티티 집합(타입)들 사이의 대응(correspondence), 즉, 사상(mapping)을 의미합니다.
관계는 관계차수와 선택성을 나타내는 엔티티 간의 였관성을 말합니다. 하나의 관계에 실제로 참여할 수 있는 인스턴스의 수를 카디날리티 (Cardinality : 관계의 대응 엔티티 수) 라고 하는데 하나의 엔티티에 대해 다른 엔티티가 몇 개 참여하는지에 따라 관계의 유형은 일대일(1:1), 일대다(1:N). 다대다(N:M)로 나뉩니다.
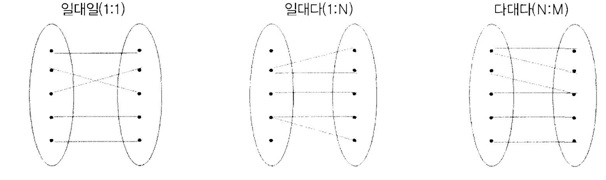
두 엔티티 간의 업부적인 연관성을 나타내는 관계는 엔티티 사이의 실선으로 나타냅니다
'oracle' 카테고리의 다른 글
| oracle 1개월차 심화학습 (0) | 2016.05.30 |
|---|---|
| datadump expdp/impdp (0) | 2016.05.09 |
| 그룹함수 (0) | 2016.05.04 |
| Transaction ACID (0) | 2016.05.03 |
| Natural Key & Surrogate Key (0) | 2016.05.03 |